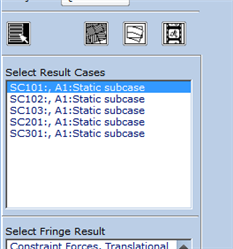
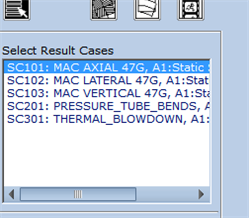
Right now I must use op2 or xdb format because those formats include the subcase names. For some reason I get no subcase names with h5. I just get the subcase number but no names in Patran. Please let me know what I am doing wrong. Surely someone at MSC knows the value of subcase names instead of just numbers. I would like to use h5 format since it is the latest and greatest. The name is supposed to come from the SUBTITLE command in the nastran input file.
Attached Files (2)