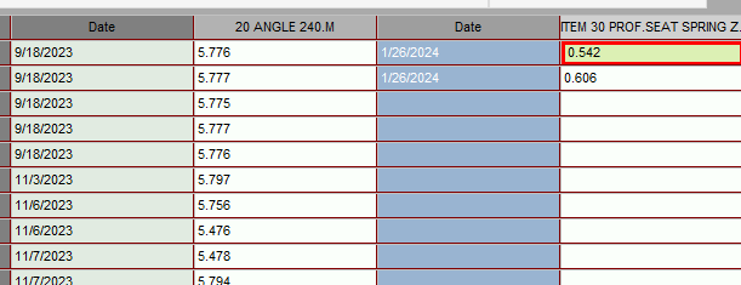
I have a couple of questions and just need verification. We made changes in a couple of pcdmis programs with a dimension when it transfers to q-stat the data from the update does not stay with the data it was output with. I have attached a screen shot as you can see the new data Item 30 is dated 1-26 but is in the row of 9-18 data. Is there a setting that would put the new data in the same row it was measured in, instead of the of beginning of the database? Or do we have to create a new database? We are hoping we don't have to create a new database for small changes but if that is what we will have to do then we will.